이러니 저러니해도
결국 나는 visionAI를 해야하나보다.
이번엔 매번 쓰던 yolo 시리즈 말고 다른 라이브러리를 사용해보았다.
바로 Detectron2!
깃 주소는 위 링크를 따라가면 된다.
오색 찬란한 README가 우릴 반겨준다.

segmentation과 keypoint 등등 지원하나보다.
개발자로써의 내 소명은 전 세계의 학자들이 머리싸매서 만들어놓은 라이브러리를 "감사하게" 생각하며 잘 쓰자 이므로,,, 부딪혀보면서 배워보자.
segmentation이니 우선, 이미지와 어노테이션이 필요한 것은 당연한 사실.
튜토리얼 따라가봤는데,,, 솔직히 튜토리얼도 좋지만 내 입맛에 맞는 데이터를 직접 학습하는게 제일 배우는게 빠르지않나 생각한다.
이미지는 여러분들이 원하는 것으로 수집하자.
어노테이션은 roboflow이라는 웹을 사용한다.
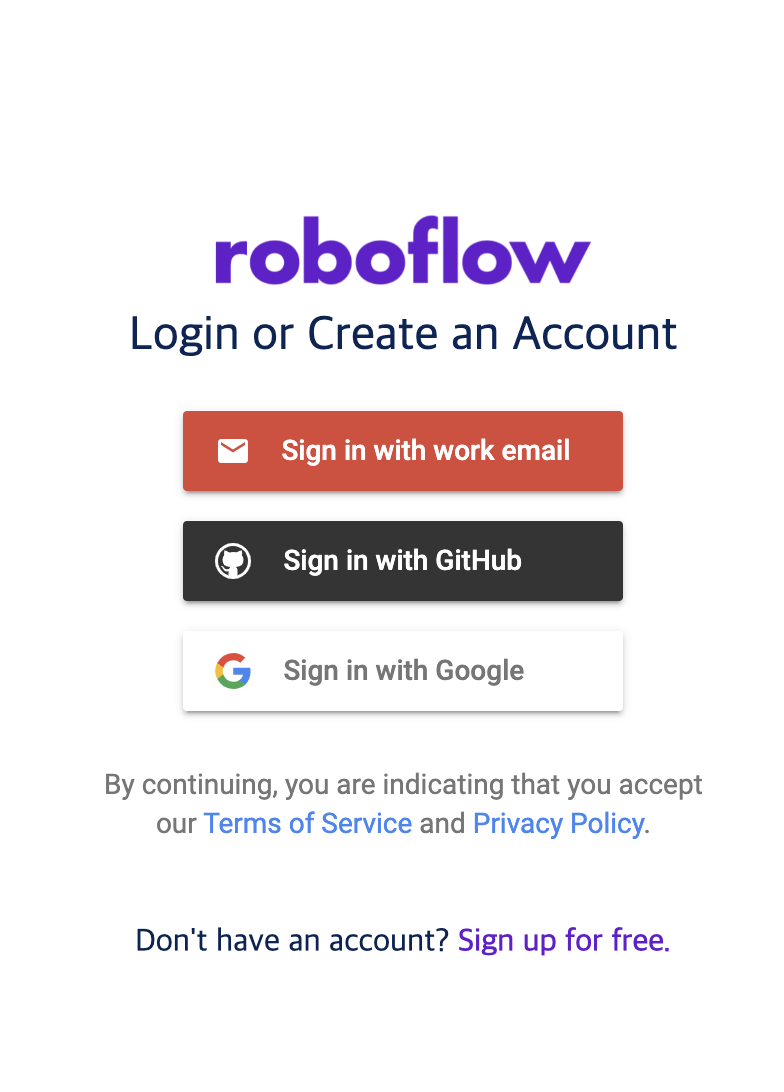
간단하게 연동해서 사용할 수 있다. 참 편리하다. ( 굳이 연동하지않아도 된다. 이메일 + 패스워드만있으면 프리패스 )
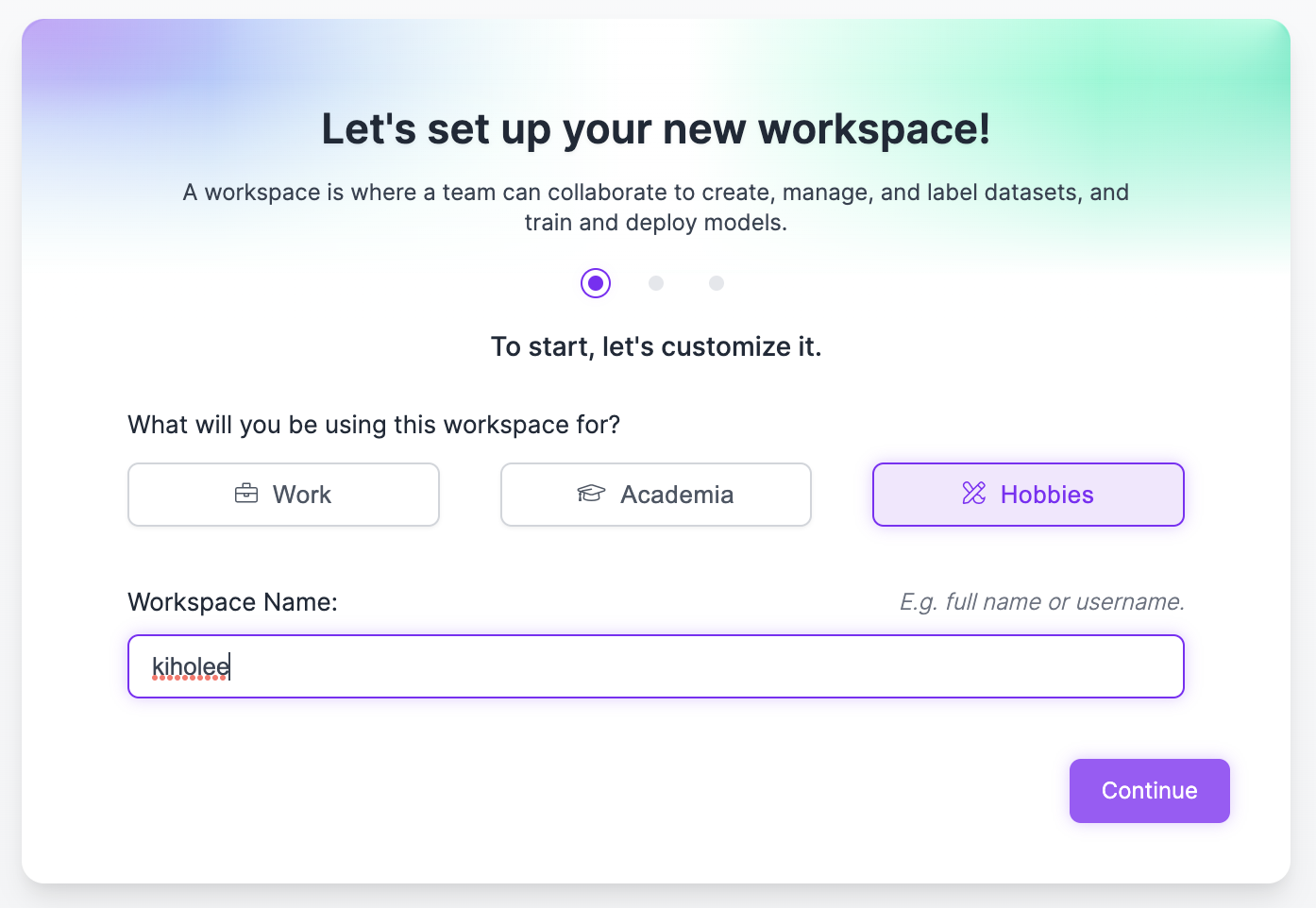
이름, 추천인 비즈니스인지 물어보는데 쿨하게 넘겨버리자.
가이드 튜토리얼 진행할지 물어본다. 영어에 자신있으면 튜토리얼 진행하고 자신없으면 감내하고 진행하자.
모름지기 공식 사이트에서 친절하게 가르쳐주는데 마다할 이유가 없다.
튜토리얼 다 끝냈으면 이미지를 직접 업로드 하자.
일단 간단하고 유용한 기능설명을 위해 제공해주는 샘플데이터를 활용해보자.
Hard Hat Sample이라는 프로젝트 ( 가 아니어도 상관없다. 이 친구들이 언제 마음이 변해서 이미지가 바뀔지 누가 알겠는가 )
를 눌러서
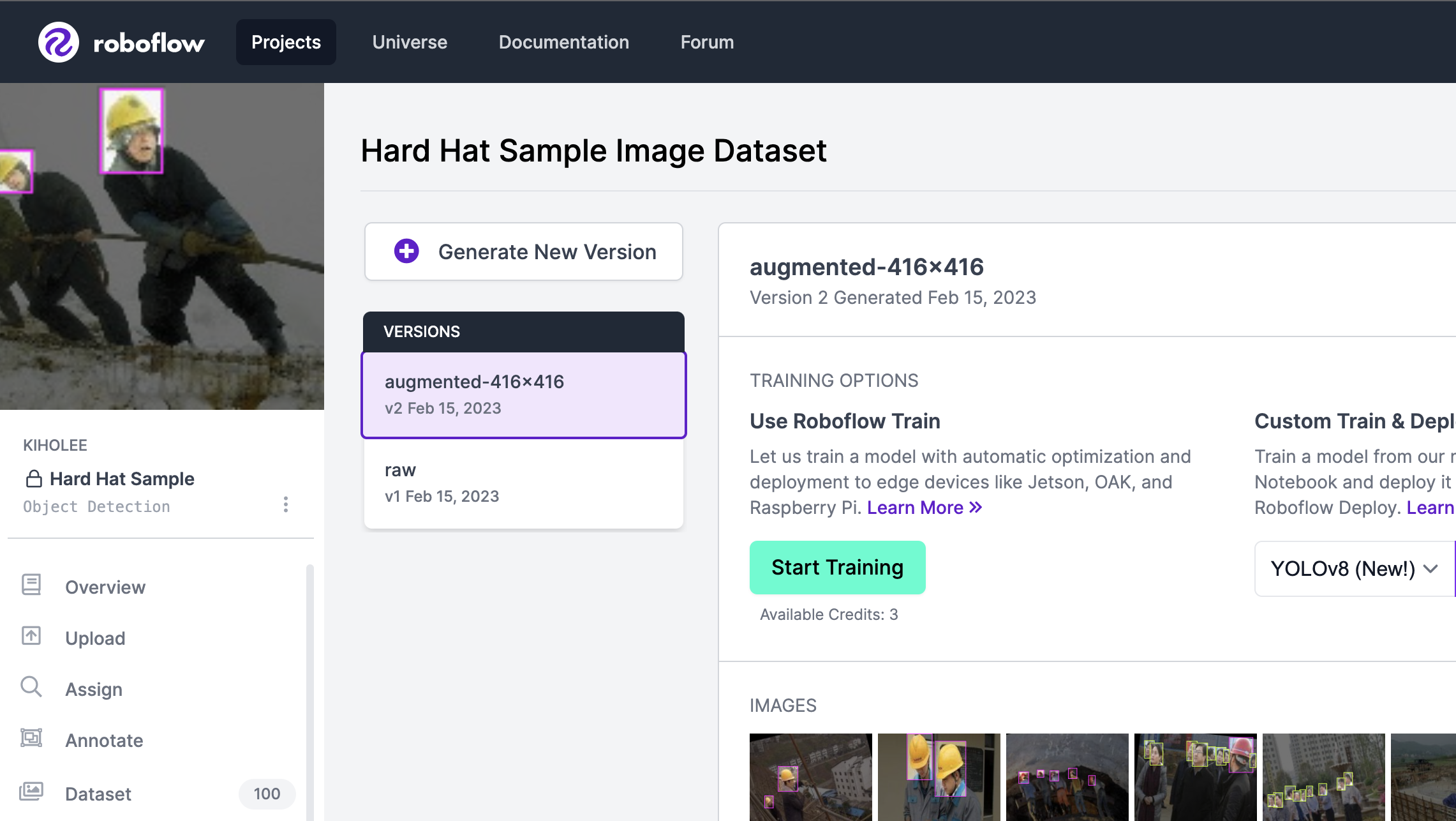
Dataset이라는 목록을 눌러보자
아무 이미지나 눌러서 들어가보면, 어노테이션을 진행할 수 있는데,

위에서부터
어노테이션 이동
바운딩박스
폴리곤
자동영역 ( <<< 신세계였습니다 )
추천 ( 공개된 모델 기반으로 추천 해줍니다)
반전 등등 있지만 자동영역까지만 활용하면 될 것 같습니다.
어노테이션이 끝났으면 Generate 탭에 들어가서 학습 데이터를 생성하면 됩니다.

train/test 분할, 전처리, 확장등등 입맛대로 생성할 수 있다.
4단계까지 진행하고나서 Generate를 누르면 잠시 뒤에 완료문구가 뜨면서

이런 화면이 나오는데, Export를 눌러 다운로드할 수 있다.

우리는 Detectron2를 사용할 예정이므로 JSON COCO데이터 형태로 다운로드 하자.
물론, Yolo의 Segmentation형태로 변환하면 txt format으로 다운로드 가능하니 원하는 라이브러리에 맞는 어노테이션 포멧으로 바꾸자.
Detectron은 시작도 안 했는데 참 길어졌다.
아래의 코드들은 모두 튜토리얼 ( 풍선 )에서 약간 수정했으며, 저도 코드 뜯어가며 배우는 입장이라 틀릴 수 있습니다.
설치는 튜토리얼에서 따라오시면 됩니다...!
# import some common detectron2 utilities
from detectron2.engine import DefaultPredictor,DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog
from detectron2.structures import BoxMode
import cv2
import os
import numpy as np
import json
import random
import itertools우선 import 목록입니다. detectron2와 cv2, numpy 등 필요한 라이브러리 설치가 필요합니다.
1.8 이상의 pytorch도 필요한 것으로 알고있습니다.
def get_data_test(img_dir): # 디렉터리를 인자로 받습니다.
json_file = os.path.join(img_dir, "_annotations.coco.json") #roboflow에서 json은 _annotations.coco.json 파일명이고, os.join합니다.
with open(json_file) as f: #json을 읽어주고
imgs_anns = json.load(f)
images = imgs_anns['images']
for i in images:
i.setdefault('annotations',[]) #images에 annotations 이라는 key를 만들어줍니다.
i['file_name'] = os.path.join(img_dir,i['file_name']) # filename을 변경해주고
for i in imgs_anns['annotations']:
tmp = i.copy()
tmp['bbox_mode'] = BoxMode.XYWH_ABS # BoxMode를 생성해줍니다. XYWH_ABS는 bbox를 나타내는 방식입니다. ( x, y , w , h) 형태라는 의미입니다.
images[i['image_id']]['annotations'].append(tmp)
return images여기서부터 제 입맛대로 수정한 함수인데, roboflow에서 export한 데이터를 detectron에서 사용하는 데이터로 변환하는 함수입니다.
roboflow에서 데이터를 받으면 아래와 같은 json파일이 train,val,test별로 생성됩니다.

detectron2의 표준 데이터셋은 아래와 같다.

전문은 여기서 확인해볼 수 있다.
거두절미하고 roboflow json에서 어노테이션이라는 key를 만들고 bbox_mode를 추가해주는 함수이다.
# DatasetCatalog.clear() 만약 실수로 이미 등록되었다는 에러메세지가 나오면 clear 함수로 초기화 시켜줍니다.
DatasetCatalog.register("your_dataset", lambda :get_data_test(<dataset_path>)) #데이터셋 이름을 입력하고, 위의 함수를 실행시키기 위해, 데이터셋의 경로를 지정합니다.
MetadataCatalog.get(<dataset_path>).set(thing_classes=[<classes>]) # 마찬가지로 경로를 지정하고, 해당 데이터셋의 클래스들을 추가합니다.
metadata = MetadataCatalog.get(<dataset_path>)detectron2는 custom dataset을 사용할 때, 따로 등록하는 과정이 필요한데, 위의 코드를 참고하면 된다.
cfg = get_cfg()
cfg.merge_from_file("./configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
cfg.DATASETS.TRAIN = ("your_dataset",) # << 필수 변경
cfg.DATASETS.TEST = () # no metrics implemented for this dataset
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = "detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl" # initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough, but you can certainly train longer
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset
cfg.MODEL.ROI_HEADS.NUM_CLASSES = <len classes> # << 필수변경
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)위의 config들은 자유롭게 수정이 가능하지만, 필수변경이라고 적어놓은 곳은 데이터셋에 맞게 수정해야한다.
이외의 부분은 파라미터 튜닝하면서 변경하면 된다.
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") # path to the model we just trained
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set a custom testing threshold
predictor = DefaultPredictor(cfg)trainer로 학습하고 predictor로 예측 준비를 하자.
from detectron2.utils.visualizer import ColorMode
project_name = 'test'
os.makedirs(f'output/result/{project_name}',exist_ok=True)
dataset_dicts = get_data_test(f"tire/{project_name}")
for i,d in enumerate(dataset_dicts):
im = cv2.imread(d["file_name"])
outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
v = Visualizer(im[:, :, ::-1],
metadata=metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imwrite(f'output/result/{project_name}/result_{i}.png',out.get_image()[:, :, ::-1])
#cv2.imshow(out.get_image()[:, :, ::-1])server전용 ubuntu에서 jupyter로 학습을 진행해서인지 튜토리얼에 나와있는 cv2.imshow에 자꾸 destroy되서 그냥 저장하는 방식으로 바꿔버렸다.
gui가 제공되는 환경이라면 맨 마지막줄을 주석해제하고 저장하지않아도 된다면, imwrite를 주석처리하고 실행시키면 된다.
개인적으로 yolo와 비교해서 성능 자체는 detectron2가 좀 더 나은 것 같다.
'python > AI' 카테고리의 다른 글
| [Roboflow] roboflow export했는데 일부분만 받아졌나요? (0) | 2023.04.28 |
|---|---|
| [이미지 학습AI] 이미지를 학습으로 annotation을 해보자.[2] (0) | 2022.07.07 |
| [AI] Semantic Segmentation을 해보자. feat.Custom dataset (0) | 2022.07.04 |
| [이미지 학습AI] 이미지를 학습으로 annotation을 해보자.[1] (0) | 2022.03.15 |