이전 회사에서 이미지학습이 지겨워 탈출했는데,
그런 말이 있지않은가. 도망친 곳에 낙원은 없다. 라고
이직한곳에서도 비슷한 일을 하게 되었다.
각설하고 이번엔 ai hub에 있는 이미지 데이터를 사용해서 객체 탐지를 진행해보고자 한다.
우선, 학습에 사용된 스펙은 다음과 같다.
| server | Ubuntu20.04 |
| torch | 1.7.1+cu110 |
| torchvision | 0.8.2+cu110 |
| cuda | 11.2 |
| gpu | RTX A4000 |
객체 탐지에 사용될 소스는 yolov5이다.
https://github.com/ultralytics/yolov5
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
여담으로 yolo v5이지만, v3이 공식적으론 끝이고 v4,v5는 원작자와 다른 개발자들이 추가했다고 알고있다.
yolo에 있는 튜토리얼을 그대로 따라가도 좋다. README만 잘 읽어도 학습 자체엔 무리가 없다.
대신, 우리는 ai hub라는 국내 서비스를 활용해서 학습을 진행하고자한다.
물론, 여러분들이 이미지학습에 대한 큰 지식이 없더라도 괜찮다. yolo v5에서는 대부분의 구조들을 제공하고있고,
우리는 사용만 하면 되기때문. 이미지 처리를 자세히 알고있다면 당연히 도움이 되지만 몰라도 학습은 가능하다.
홈 | AI 허브
상단으로Back to top AI 데이터를 찾으시나요? AI 학습에 필요한 다양한 데이터를 제공합니다. 원하시는 분야를 선택해 보세요.
aihub.or.kr
위의 사이트에 들어가서 회원가입을 진행하자.
아래와 같은 폼을 채워주고 가입을 완료하자.

로그인을 하고나면, 아래의 화면이 보일텐데, 생각보다 많은 데이터를 개방하고있다.
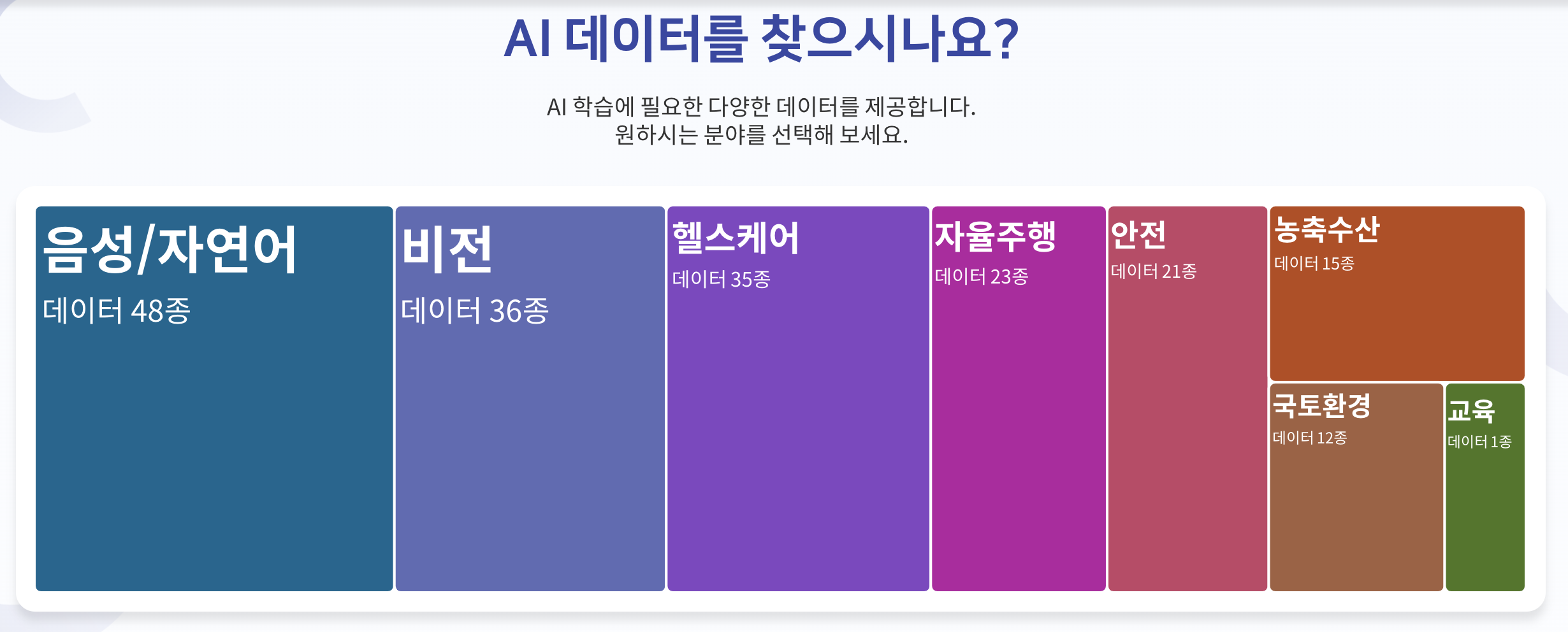
우리는 이미지 학습을 진행하고자 하기때문에, 비전 카테고리로 접근하자.
상당히 많은 데이터들이 있는데, 데이터를 고르기 전에,
1. 이미지데이터 위주로 되어있는 데이터셋.
2. 폴리곤이 아닌 bounding box.
이 두가지를 고려해서 선택한다.
yolov5는 물론 영상처리도 가능하지만, 아직 영상은 경험이없어서 확인하기 어렵다.
객체 탐지가 목적으로, 세분화된 폴리곤보다는 바운딩박스로 객체를 탐지하는데 우선순위를 둔다.
데이터를 골랐다면, 우선 데이터 신청을 진행하자.
개인사용자는 어떨지 모르겠지만 내 경우엔 바로 다운로드가 가능하게 승인처리가된다.
하지만 원천데이터셋의경우, 데이터량이 100기가단위를 훌쩍 넘어버리기 때문에, 샘플데이터로 만족하자.
우선 나는 https://aihub.or.kr/aidata/34145의 상품 이미지로 선택했고, 샘플데이터를 다운받았다.
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=64
aihub가 리뉴얼을해서인지 기존의 url이 전부 바뀌어버렸다,,,,
열어보면, 아래와 같은 구조이고 세부적으로 이미지파일과 메타데이터가 함께 VOC포멧으로 저장되어있다.

yolov5를 클론하고 위의 샘플데이터를 받았다면, 일단 이 포스트의 목적은 달성했다.
'python > AI' 카테고리의 다른 글
| [Roboflow] roboflow export했는데 일부분만 받아졌나요? (0) | 2023.04.28 |
|---|---|
| [이미지 학습 AI] Detectron2를 사용해보자. (0) | 2023.02.15 |
| [이미지 학습AI] 이미지를 학습으로 annotation을 해보자.[2] (0) | 2022.07.07 |
| [AI] Semantic Segmentation을 해보자. feat.Custom dataset (0) | 2022.07.04 |