이전 포스트에서 대시보드가 보였다면, 이젠 사용자 인증정보를 생성해보자.

당장은 Youtube API 만 사용하려고하니, API 선택에서 위와같이 유튜브를 찾고, 공개데이터를 선택한 뒤, 다음단계로 가자.
다음으로가면, API 키 제한을 하라고한다. KEY 값이 외부로 유출되면, 연결된 결제수단으로 과금이 발생할 수 있으니
제한이 필요하다는것.
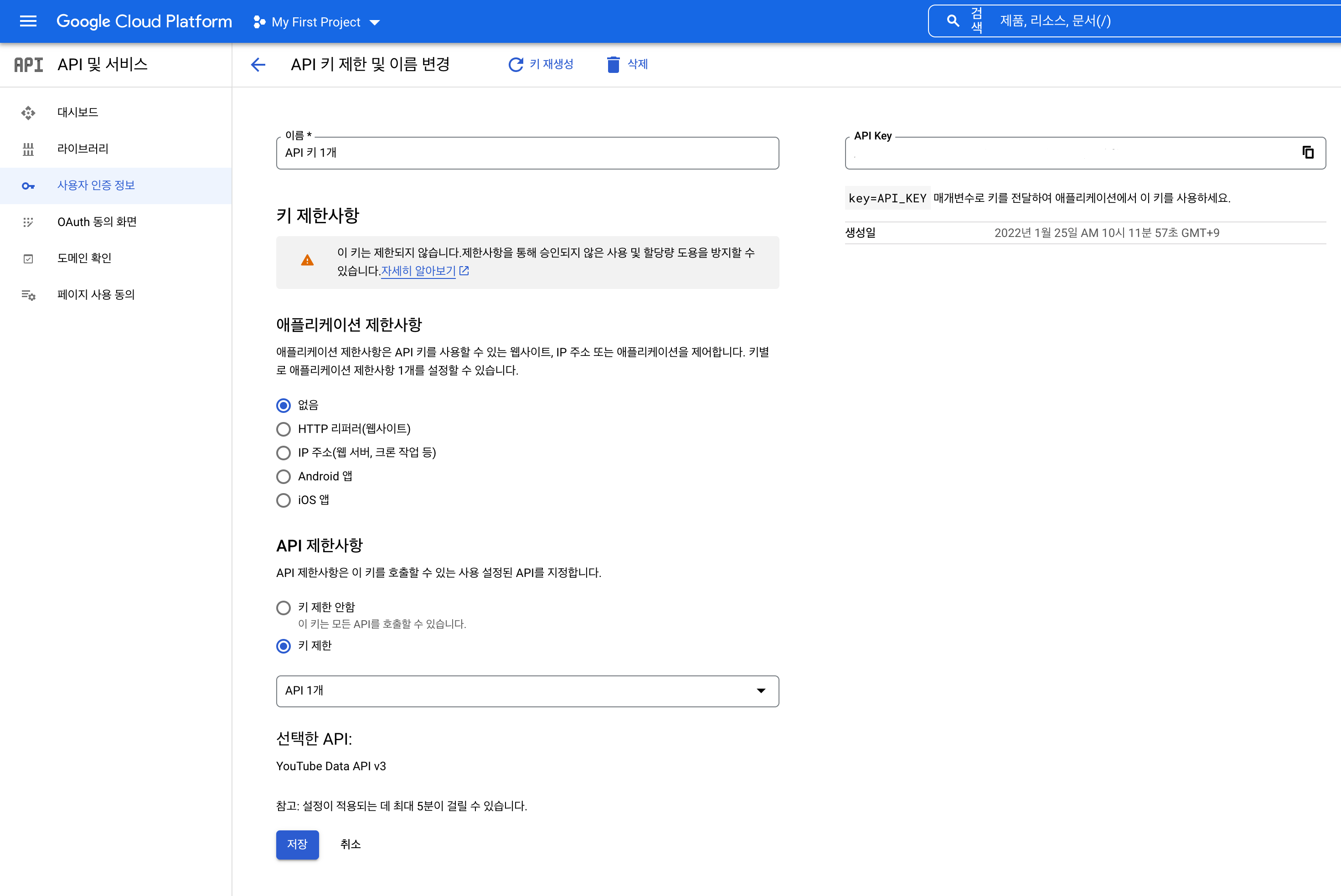
이름도 따로 정할 수있는데, 난 귀찮은 관계로 넘어간다.
관리해야하는 API가 여러개라면 고려할만한 옵션이다. 저장을 누르고 API를 복사해놓자.
트위터와는 다르게 KEY만 가지고있으면 접근이 가능하다.
pip install google-api-client위 명령어로 google client를 설치하면 일단 사용준비는 끝.
from googleapiclient import discovery
KEY = 'YOUR_KEY'
youtube = discovery.build('youtube', 'v3', developerKey=KEY,
cache_discovery=False) # file_cache is unavailable when using oauth2client >= 4.0.0 or google-auth오류로 추가함.
search = 'python'
req = youtube.search().list(q=search, part='snippet', type='video',
maxResults=100,
# publishedAfter = (now-datetime.timedelta(days=30)).isoformat()+'Z',
order = 'viewCount',
pageToken=None
)
res = req.execute()search에 유튜브에서 검색하고자하는 검색 키워드를 입력하면 된다.
이 포스팅에선 python을 키워드로 넣어줬다.
publishedAfter는 주석처리했지만, 해당 시점 이후로 업로드된 동영상만 조회하는 옵션이다.
maxResults는 몇개의 동영상을 반환할지,
order는 정렬기준을 어떤 값을 기준으로 할지이다.
저대로 실행시키면, res에 값이 떨어진다.
maxResults의 영상들이 조회되고, items에 자세한 내용들이 list 형태로 담겨져있다.
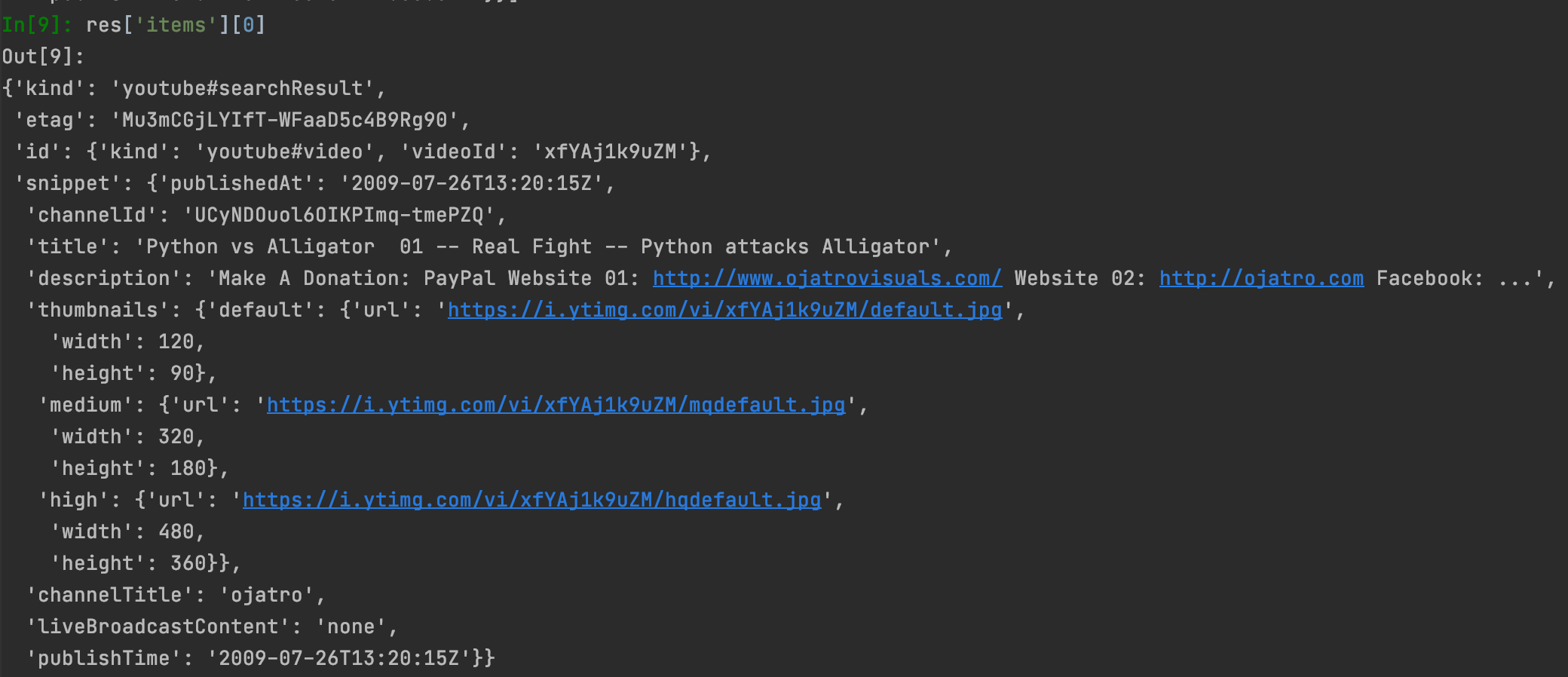
2009년에 업로드된 'Python vs Alligator 01 -- Real Fight -- Python attacks Alligator', 이라는 영상이다.
실제로 유튜브에 조회하면 동일한 결과를 얻는다.
유튜브의 영상의 상세 내용을 알기위해선 위의 search를 통해 얻어낸 items의 id가 필요하다.
바로 위 코드뒤에 아래와 같이 붙여넣자.
id = res['items'][0]['id']['videoId']
stats = youtube.videos().list(part = ['snippet','statistics'],id = id).execute()이번엔 실행까지 한 결과를 담았다.
json형태로 반환되는데, 우리가 원하는 조회수를 얻기위해선 깊게 들어가야한다.
stats['items'][0]['statistics']
#{'viewCount': '125024935',
#'likeCount': '166822',
#'favoriteCount': '0',
#'commentCount': '16041'}자, python으로 검색된 결과에서 조회수가 가장 많은 영상의 조회수와 좋아요수, 댓글 수 까지 가져와보았다.
'python > 크롤링' 카테고리의 다른 글
| [구글 API] 구글 API를 통해 유튜브를 검색해보자 -1 (0) | 2022.01.25 |
|---|---|
| [파이썬 크롤러] 나는 로봇이 아닙니다. header (2) | 2021.09.09 |
| [파이썬 크롤러] Tweepy를 이용한 트위터 크롤링 [3] (2) | 2021.08.17 |
| [파이썬 크롤러 ] Tweepy를 이용한 트위터 크롤링 [2] (0) | 2021.07.30 |
| [파이썬 크롤러] 셀레니움을 이용한 크롤링[2] (2) | 2021.07.29 |